Increasing Searches for ZIP Files
I noticed recently that we have more and more requests for ZIP files in our web honeypot logs. Over the last year, we have had a substantial increase in these requests.
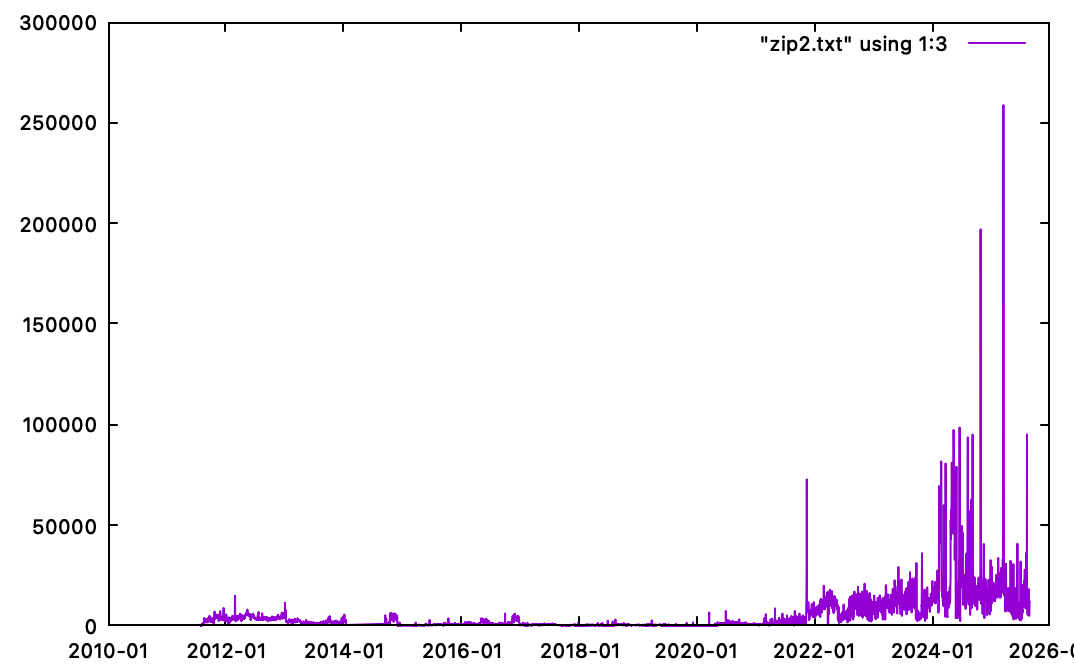
Here are some of the most common URLs requested so far this year:
| url | c |
|---|---|
| /backup.zip | 10977 |
| /web.zip | 9701 |
| /www.zip | 9414 |
| /html.zip | 9361 |
| /data.zip | 9047 |
| /src.zip | 8938 |
| /bin.zip | 8816 |
| /old.zip | 8790 |
| /upload.zip | 8700 |
| /source.zip | 8131 |
The URLs are not specific to any vulnerability. Instead, they are likely filenames selected by administrators for ad-hoc backup files.
And the list of URLs tested is getting longer and longer. Here are some that showed up for the first time today:
| url | firstseen | count |
|---|---|---|
| /modules.zip | 2025-08-26 | 18 |
| /env.production.zip | 2025-08-26 | 16 |
| /cmd.zip | 2025-08-26 | 16 |
| /session_data.zip | 2025-08-26 | 16 |
| /composer.lock.zip | 2025-08-26 | 16 |
| /pkg.zip | 2025-08-26 | 16 |
| /cloud-config.zip | 2025-08-26 | 15 |
| /ssh_keys.zip | 2025-08-26 | 15 |
| /hooks.zip | 2025-08-26 | 15 |
| /composer.json.zip | 2025-08-26 | 14 |
Of course, one should never have "random" backup zip files exposed on a web server like this. But we all know it happens. Your best defense is likely to first of all try to prevent downloading of zip files, if that is an option, but adjust the web server configuration. Secondly, you should monitor the document root directories for any rogue zip files.
Ultimately, good change control should be your defense to prevent files like this from being dropped on a web server by either system administrators or developers.
--
Johannes B. Ullrich, Ph.D. , Dean of Research, SANS.edu
Twitter|


Comments